WebエンジニアによるLLMの基本をざっくり理解するノート 第一弾 「ベクトル化とは?」
WebエンジニアによるLLMの基本をざっくり理解するノート
LLM(大規模言語モデル)を活用したシステム開発において、Webエンジニアとして知っておきたい基本的な知識や概念、大まかな仕組みをできるだけ簡単にまとめていきたいと思います。
現在、クレアヴォイアンスではRAGを使ったシステムを開発していますが、このノートは私自身の理解を深めるためのおさらいも兼ねています🤤 基本的には具体的なアルゴリズムや数式、計算などの詳細には踏み込まず、概念や全体像をつかむことを優先してまとめていきます。
(基本的に前半はそのコンセプトで)
ベクトル化とは
大雑把に言えば「単語や文章の意味を機械がわかるように数値化(ベクトル化)したもの」ということになります。
例えば以下のようなクイズがあるとします。
問題: ?に当てはまる言葉はなんでしょう
King - Man + Woman = ?
1. Uncle
2. Queen
3. Grandmother答えはQueenとなりますが、この問題を機械が計算によって解くことができるのです。
どうやって?
たとえば、各単語を「性別」と「高貴さ」の2つの軸で数値にし、2次元グラフに表してみるとします。
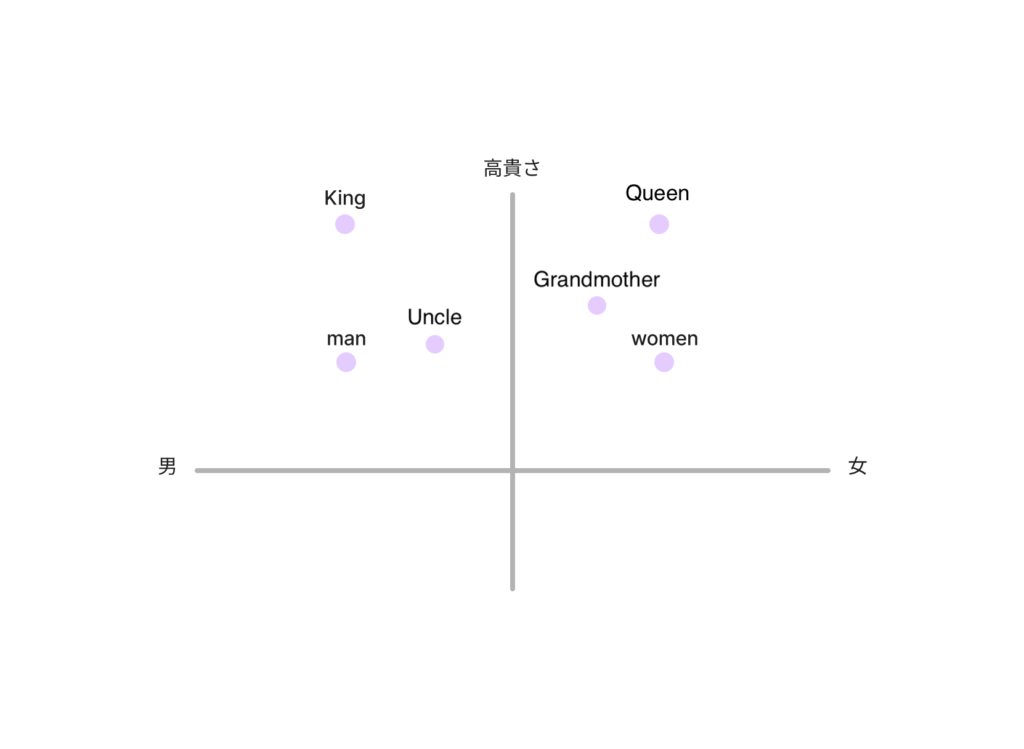
すると「King - Man + Woman」の位置は、ちょうど「Queen」に近くなるような計算結果になります。
もちろん、実際の言葉の意味はそんなに単純ではありません。
現実では、「性別」や「高貴さ」だけでなく、数千もの数値(1000〜3000ほど)を使って表現されます。
またこれは言葉の意味だけでなく文法的な知識も持っており、例えば slow → slowly, quick → ?(quickly) などの問題も解けます。
この1000〜3000個の数値を1つの1000〜3000次元ベクトルとして扱うということが単語をベクトル化するということになります。
このベクトルの値は、人間が手で設定するのではなく、大量の文章データを使ってディープラーニングで自動的に学習されたものです。
そのため、各次元が人間にとって意味のある軸とは限りませんが、結果として言葉同士の「意味的な距離感」をうまく捉えられるようになっています。
単語や文章をベクトル化することをEmbeddingと言い、例えばOpenAIのAPIを呼び出せば気軽にベクトル化することができます。
https://platform.openai.com/docs/guides/embeddings/embedding-models
ベクトル化を使って何ができるのか
ベクトル化のすごいところは、意味の近さも数値として扱えるようになる点です。さっき紹介したような計算だけでなく、「似ているベクトル」を探すということもできます。
先ほどは「単語」をベクトルにする話でしたが、実は文章全体や文書の塊も、1つのベクトルで表現できます。
これにより、ユーザーの質問と「意味的に近いドキュメント」を自動的に探し出すことが可能になります。
たとえば、こんな感じです。
① 検索された文章
「xxxxxの使い方」
② 似ていると判断されたドキュメント
「xxxxxはooooのような方法で使うことができます。」
このように、キーワードが完全に一致していなくても、「意味が近い」と判断して関連情報を見つけ出せるのが、ベクトル化の大きな強みです。
気になる人向け:学習についてもうちょっと深掘ってみる
じゃあベクトル化自体はどうやって学習されたのかについて書いていきたいと思います。
今回は単語のベクトル化の基本手法word2vecのCBOWモデルを参考にしてざっくりイメージを書き留めます。(OpenAIのAPIなどのEmbeddingはもっと応用的な手法を使っています。)
word2vecでは、文章の穴埋め問題を解くタスクのモデルを学習によって作り出すことで、単語のベクトル表現を獲得できます。ある文章のある単語を穴とし前後〇個分の単語を渡して予測してもらう、というプロセスを大量のテキストで学習します。(〇個分は学習のコストとか精度を左右するのであろう)
例えば ? is a woman という穴埋め問題を解くとしましょう。
学習するテキスト全体の語彙数をVとし、単語の次元数をhとすると、モデル構造のイメージ図は以下です。(重みは学習で変更されるパラメータ)
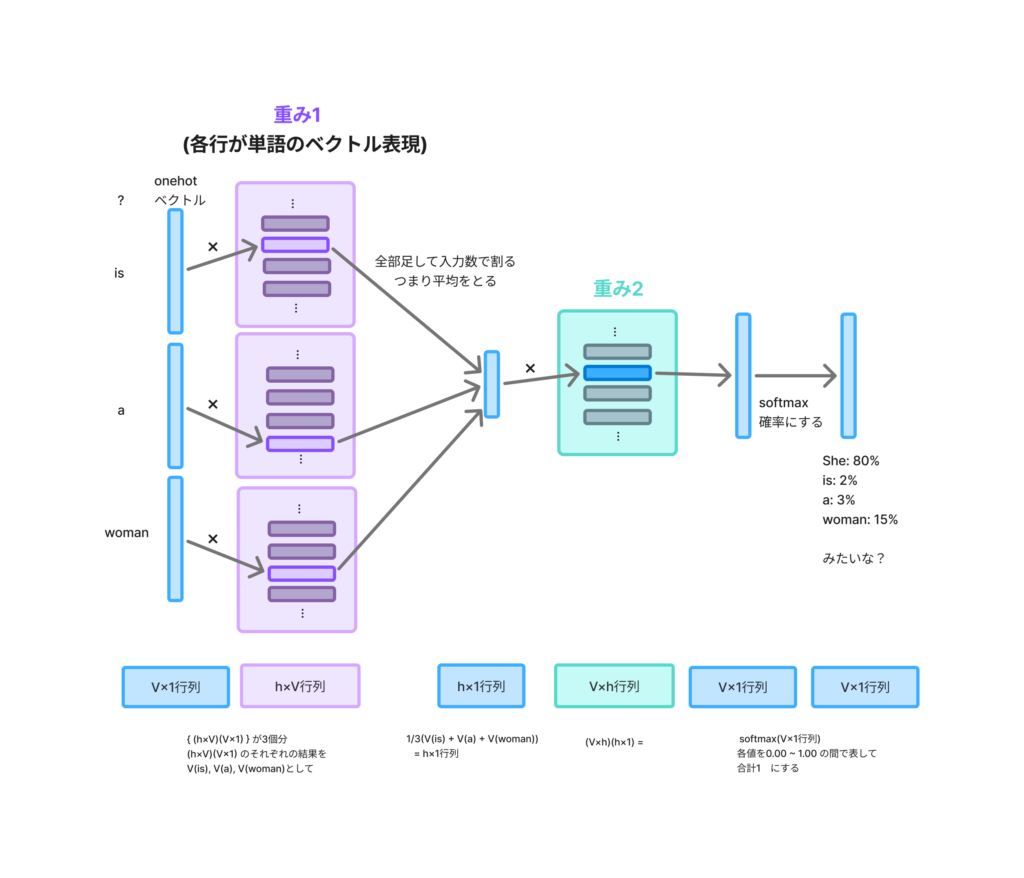
①最初の入力は配列のindexの位置のようなものです。例えばisの入力値は、語彙数が4で(She,is,a,woman)、isが2番目だとしたら以下の入力になります。V×1(4×1)の行列になります。
[
[0]
[1]
[0]
[0]
]②各入力に重み1をかけます。重み1は単語のベクトル表現となるところです。各列が単語のベクトル表現に対応します。
(プログラマー的には各行が単語のベクトル表現にあたると説明した方が楽なので、以下のコードにしてます。行列の計算上 h×V行列と逆になります)
//語彙数が4だとしたら
[
[0.00034, 0.265069, 0.83434, ...]
[0.35357, 0.563639, 0.36734, ...] //ここがisのベクトル表現
[0.65034, 0.245069, 0.45434, ...]
[0.20234, 0.650696, 0.34347, ...]
]③そして各結果を足して入力数で割って平均します。
④ ③の結果に対して重み2をかけます。この重み2は穴の部分が何の単語であるかの確率を出すため、結果がV×1行列になるような行列となります。
//計算結果
[
[1.6]
[0.2]
[0.1]
[0.1]
]
//みたいな…⑤ 確率としてわかりやすくするために全部足して1になるようにするsoftmax関数をかけます。
[
[0.8] //Sheの確立が80%!
[0.1]
[0.05]
[0.05]
]学習を繰り返すことで、重み1と重み2のパラメータの精度がよくなっていくイメージです。
このモデルをさらに日本語訳するとしたら
入力された単語をベクトルとして表現し、その結果を平均化して入力全体の「特徴量」を表し、その特徴量から次の単語の確率を予測する。 となるのかなーと思います。
最初の層が単語のベクトル化になる理由は、入力された単語がどんなものなのか知ってテキストの特徴を知る必要がある、つまりパラメータとしてh次元の数値に単語の特徴を埋め込んでいると言えるのではないでしょうか。
終わりに
次回は、「似ているベクトル」を探すってどう計算するのか について書いていきたいと思います。
このword2vecについてはアリシアさんの動画めちゃくちゃわかりやすいのでおすすめです。
https://www.youtube.com/watch?v=0CXCqxQAKKQ
https://www.youtube.com/watch?v=jlmt4nY0-o0&t=671s
